















Updated at: 2022-12-09 03:49:50
Root Cause Analytics adopts decision tree algorithm, and the key variables are analyzed by statistically analyzing the influence degree of independent variable characteristics on target variables.
A complete root cause analytics task requires two parts: data preview and model computation:
• Data Preview: It is to visualize the data and dimensions that users want to analyze;
• Model Computation: It is to provide a variety of algorithms for users to select different algorithms and parameters for model computation as needed.
To create a new Root Cause Analytics, the specific steps are as follows:
1. Click Machine Learning > New to create New machine learning task, and click Help to view the Brief and Scenario for Show of the root cause analytics machine learning task, as follows:
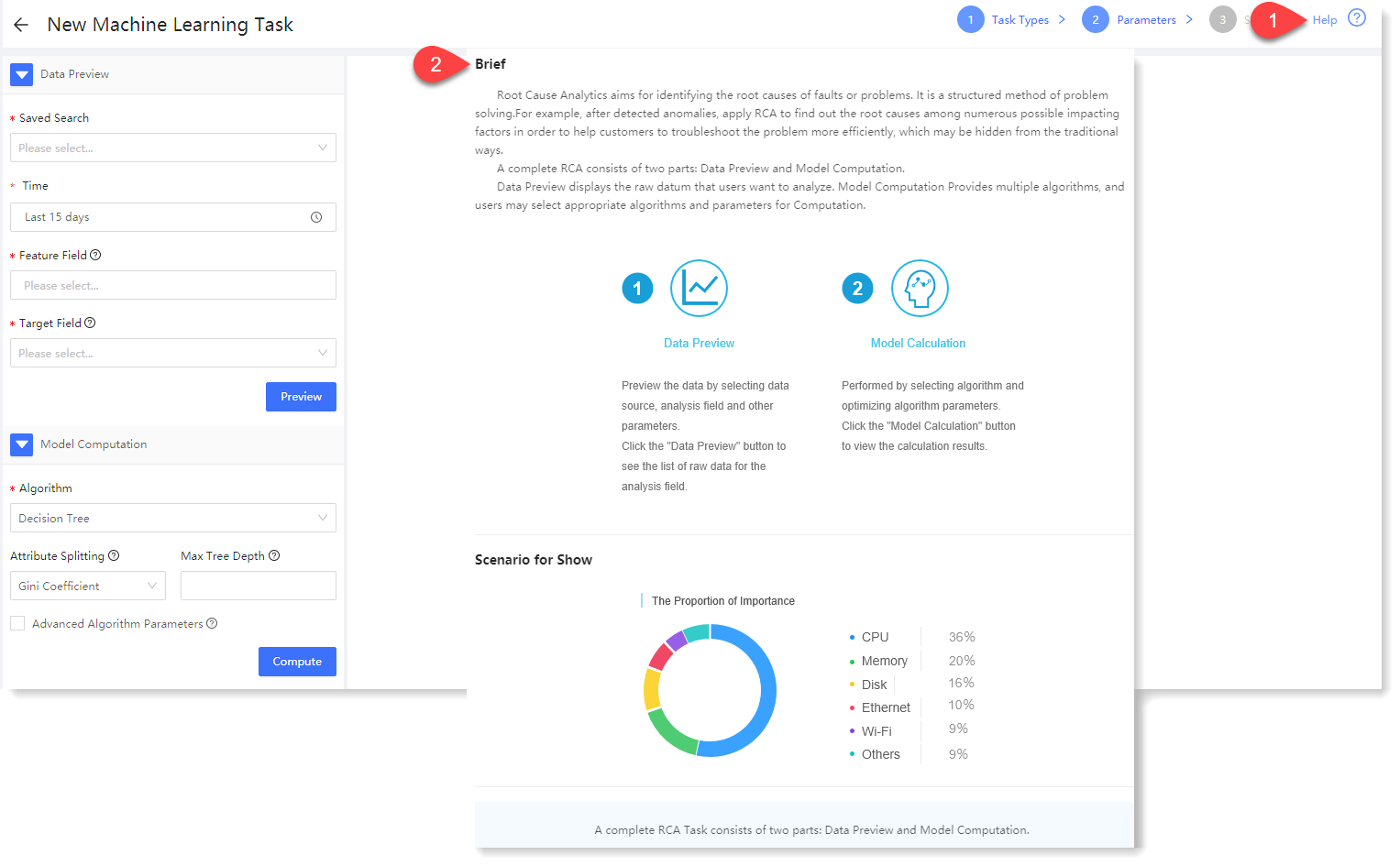
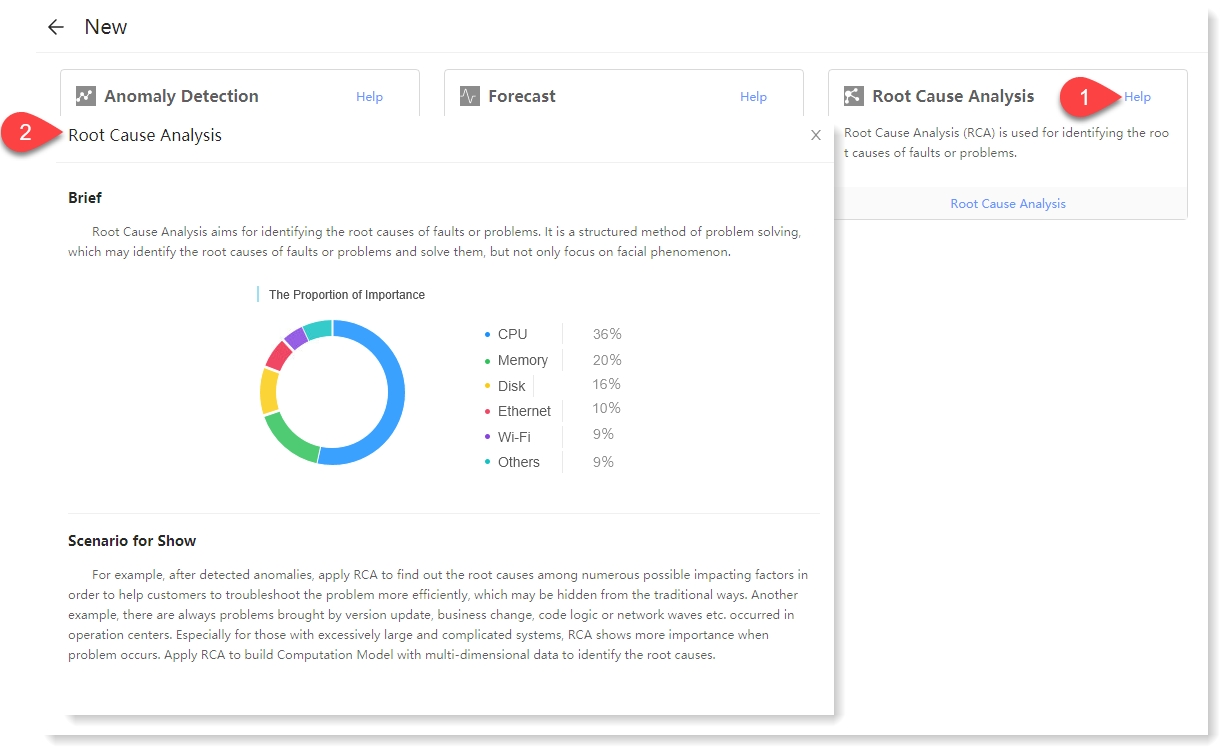 2. Click Root Cause Analytics for parameter configuration, and click Help to view the brief, usage help, parameter configuration guidance, and algorithm introduction of Root Cause Analytics, as follows:
2. Click Root Cause Analytics for parameter configuration, and click Help to view the brief, usage help, parameter configuration guidance, and algorithm introduction of Root Cause Analytics, as follows:
 3. Configure data preview: Data preview is to display the raw data of the data that users want to analyze. To configure the data preview, click Preview to view the raw data list of feature field and information field.
3. Configure data preview: Data preview is to display the raw data of the data that users want to analyze. To configure the data preview, click Preview to view the raw data list of feature field and information field.
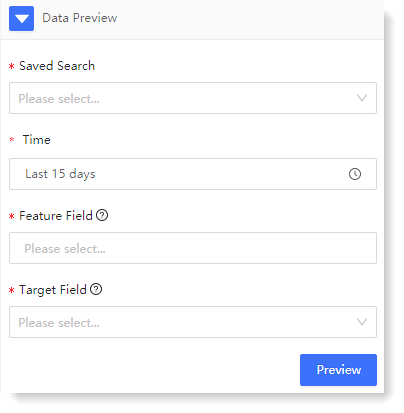
1) The configuration parameters are as follows: 2) Click Preview to view the raw data list of feature field and information field of the data preview result..
4. Configure model computation
Root Cause Analytics supports decision tree algorithm. Decision tree is a nonparametric supervised learning method, which usually adopts top-down design. For every iteration loop, an eigenvalue will be selected to bifurcate until it cannot bifurcate. Among them, the branches in the decision tree represent the decision rules (IF THEN rules), the leaf nodes in the decision tree represent the results of the IF THEN rules, and the values of the target variables can be predicted through the IF THEN rules.
The configuration parameters are as follows:
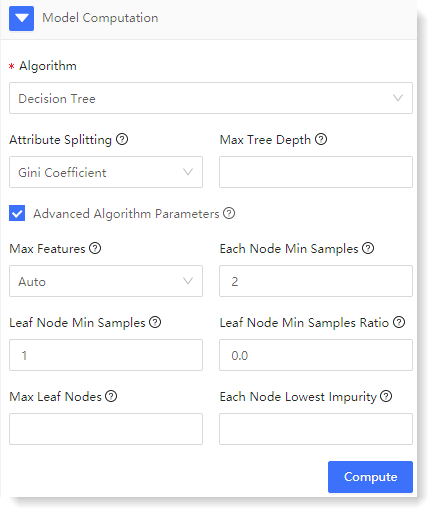
1) Configure Decision Tree algorithm parameters: 2) Click Preview to view the model computation result.
The model computation includes two parts: Importance Ratio of Feature (Cause) Field and Root Cause Rule List: 5. After completing the above configuration, click Save to fill in the machine learning task Name, and click OK to complete the machine learning task creation.
A complete root cause analytics task requires two parts: data preview and model computation:
• Data Preview: It is to visualize the data and dimensions that users want to analyze;
• Model Computation: It is to provide a variety of algorithms for users to select different algorithms and parameters for model computation as needed.
To create a new Root Cause Analytics, the specific steps are as follows:
1. Click Machine Learning > New to create New machine learning task, and click Help to view the Brief and Scenario for Show of the root cause analytics machine learning task, as follows:
2. Click Root Cause Analytics for parameter configuration, and click Help to view the brief, usage help, parameter configuration guidance, and algorithm introduction of Root Cause Analytics, as follows: 3. Configure data preview: Data preview is to display the raw data of the data that users want to analyze. To configure the data preview, click Preview to view the raw data list of feature field and information field.1) The configuration parameters are as follows: 2) Click Preview to view the raw data list of feature field and information field of the data preview result..
4. Configure model computation
Root Cause Analytics supports decision tree algorithm. Decision tree is a nonparametric supervised learning method, which usually adopts top-down design. For every iteration loop, an eigenvalue will be selected to bifurcate until it cannot bifurcate. Among them, the branches in the decision tree represent the decision rules (IF THEN rules), the leaf nodes in the decision tree represent the results of the IF THEN rules, and the values of the target variables can be predicted through the IF THEN rules.
The configuration parameters are as follows:
1) Configure Decision Tree algorithm parameters: 2) Click Preview to view the model computation result.
The model computation includes two parts: Importance Ratio of Feature (Cause) Field and Root Cause Rule List: 5. After completing the above configuration, click Save to fill in the machine learning task Name, and click OK to complete the machine learning task creation.
< Previous:
Next: >